
概念和原理
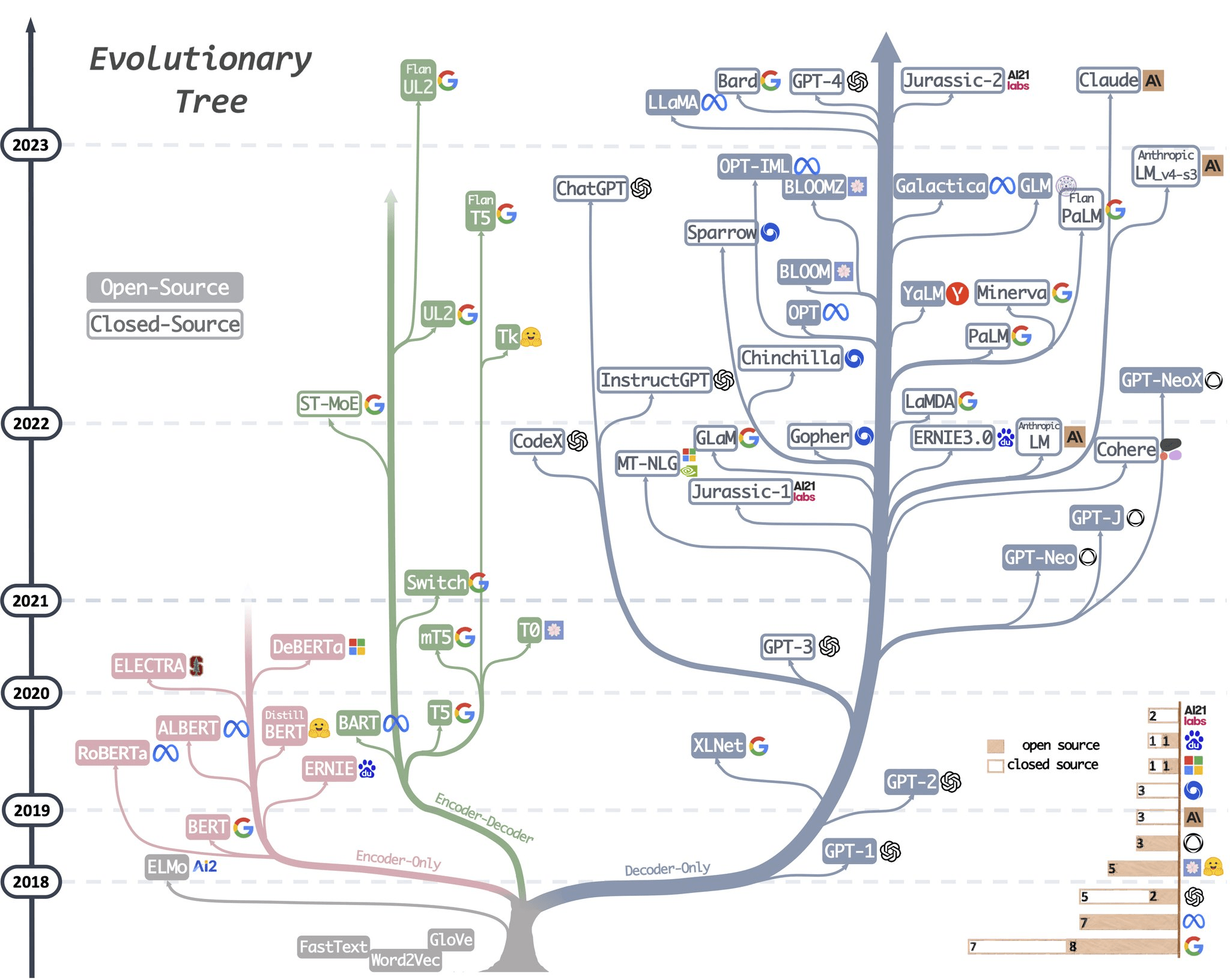
2022 年 11 月 30 日,OpenAI 正式发布了其面向消费用户的产品ChatGPT,ChatGPT 的发布标志着大语言模型(LLM: Large Language Model) 时代的到来。
各知名的大公司相继投入到对话式大语言模型的研发之中,包括但不限于谷歌、Meta、百度、阿里等
- 2023 年 2 月 6 日,谷歌宣布将推出一款聊天机器人——Bard,2 月 9 日,谷歌 Bard 发布会试演翻车,回答内容出现错误,当日市值暴跌1000亿美元。
- 2023 年 2 月 24 日,Meta 官宣 SOTA 大语言模型 LLaMA,对非商用的研究用例开源。
- 2023 年 3 月 14 日,OpenAI 发布 GPT-4
- 2023 年 3 月 16 日,百度举办“百度文心一言新闻发布会”,正式发布文心一言*。*
- 2023 年 4 月 11 日,阿里在阿里云峰会上,正式宣布推出大语言模型通义千问*。*
- 2023 年 7 月 18 日,Meta 官宣发布 LLaMA2
- 2023 年 10 月 17 日,百度在 2023 年的百度世界大会上宣布发布文心 4.0*。*
- …….
大模型:也称基础模型,是指具有大规模参数和复杂计算结构的机器学习模型,能够处理海量数据、完成各种复杂的任务。
这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。
ChatGPT对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。 当前流行的大模型的网络架构一直沿用当前NLP领域最热门最有效的架构——Transformer结构。相比于传统的循环神经网络(RNN)和长短时记忆网络(LSTM),Transformer具有独特的注意力机制(Attention),这相当于给模型加强理解力,对更重要的词能给予更多关注,同时该机制具有更好的并行性和扩展性,能够处理更长的序列,立马成为NLP领域具有奠基性能力的模型,在各类文本相关的序列任务中取得不错的效果。
根据这种网络架构的变形,主流的框架可以分为Encoder-Decoder, Encoder-Only和Decoder-Only,其中:
- Encoder-Only:仅包含编码器部分,主要适用于不需要生成序列的任务,只需要对输入进行编码和处理的单向任务场景,如文本分类、情感分析等,这类代表是BERT相关的模型,例如BERT,RoBERT,ALBERT等
- Encoder-Decoder:既包含编码器也包含解码器,通常用于序列到序列(Seq2Seq)任务,如机器翻译、对话生成等,这类代表是以Google训出来T5为代表相关大模型。
- Decoder-Only:仅包含解码器部分,通常用于序列生成任务,如文本生成、机器翻译等。这类结构的模型适用于需要生成序列的任务,可以从输入的编码中生成相应的序列。同时还有一个重要特点是可以进行无监督预训练。在预训练阶段,模型通过大量的无标注数据学习语言的统计模式和语义信息。这种方法可以使得模型具备广泛的语言知识和理解能力。在预训练之后,模型可以进行有监督微调,用于特定的下游任务(如机器翻译、文本生成等)。这类结构的代表也就是我们平时非常熟悉的GPT模型的结构,所有该家族的网络结构都是基于Decoder-Only的形式来逐步演化。
GPT的全程是Generative Pre-trained Transformer(生成型预训练变换模型)。顾名思义,它是个以预训练技术为核心的生成式模型,同时它采用Transformer这个编码-解码模型的解码部分。
其名称中的“预训练”指的是在大型文本语料库上进行的初始训练过程,其中模型学习预测文章中下一个单词,它可以完成各种自然语言处理任务,例如文本生成、代码生成、视频生成、文本问答、图像生成、论文写作、影视创作等等。
通俗来讲GPT就是通过Transformer 架构进行文本预训练后能够按照给定的文本,生成文本合理的延续的模型(文本接龙)。
例如,如果我将"We need to"作为输入提供给模型,算法可能会产生如下的结果:

ChatGPT是在GPT模型上进行了进一步的改进,通过对话式交互任务的训练,使得模型可以更好的理解和处理与人的对话的任务。
在使用 ChatGPT 的过程中,你可能还注意到模型不是确定性的:如果你两次询问完全相同的问题,你很可能会得到两个不同的答案。这是因为模型实际上并不产生一个单独的预测标记;相反,它返回了所有可能标记的概率分布。换句话说,它返回一个向量,其中每个条目表示选择某个特定标记的概率。然后模型从该分布中进行采样以生成输出标记。

模型是如何得出那个概率分布的呢?这就是训练阶段的作用。在训练过程中,模型会接触大量的文本,并且通过调整权重来预测给定输入标记序列的良好概率分布。GPT 模型是使用互联网的大量数据进行训练的,因此它们的预测结果反映了它们所见到的信息的混合。
在接触GPT的过程中我们经常会遇到一些不常见的概念,这里逐一介绍一下
词元(Token):在 LLM 中,token代表模型可以理解和生成的最小意义单位,是模型的基础单元。根据所使用的特定token化方案,token可以表示单词、单词的一部分,甚至只表示字符。token被赋予数值或标识符,并按序列或向量排列,并被输入或从模型中输出,是模型的语言构件。
对于模型而言,token 是一种数字化的表示形式。每个 token 都与一个唯一的数字 ID 相关联,模型通过这些 ID 来区分不同的 token。在训练过程中,模型学习了将文本映射到这些数字 ID 的方法,以便能够对新的文本进行编码和解码。


提示词(Prompt):在和 LLM 的交互中,提示词发挥着至关重要的作用,提示词是我们和 LLM 沟通的桥梁。通过给模型提供一个或多个提示词或短语,来指导模型生成符合要求的输出。 通过精心设计提示词,我们可以引导模型关注输入数据中的关键信息,从而提高模型在各种自然语言处理任务上的能力。

微调(SFT:Supervised Fine Tuning):对于 ChatGPT 或者文心这些大模型而言,对其进行预训练(算力、算法和数据)的成本非常大,整个训练需要数千个 GPU 并行处理才可以解决海量数据的算力问题。而仅 GPU 的成本就可能就高达数百万美元。
基于对成本的考虑,因此,预训练一个大模型并非是人人都可以做到的事情。微调是一种机器学习技术,涉及对预训练模型进行小的调整,以提高其在特定任务中的性能。因为模型已经对世界有了很好的了解,并且可以利用这些知识更快地学习新任务,因此微调比从头开始训练模型更有效,通常也会产生更好的结果。从成本的角度看,微调的成本也会比预训练大模型的成本要低的多。
模型微调的基本思想是使用少量带标签的数据对预训练模型进行再次训练,以适应特定任务。在这个过程中,模型的参数会根据新的数据分布进行调整。这种方法的好处在于,它利用了预训练模型的强大能力,同时还能够适应新的数据分布。
幻觉(Hallucination):如其他技术一样,即便当前 LLM 在各个领域中有着惊人的表现,但是 LLM 也存在着缺陷和局限。幻觉是指模型生成了看似合理但实际上并不存在的内容。这些内容可能包含虚构的信息、存在前后矛盾的逻辑、甚至是毫无意义的内容。
幻觉会严重影响依赖 LLM 的下游业务的表现,导致这些业务在真实场景中无法满足用户需求。

能力和挑战
讲了这么多的大模型,那么大模型有哪些能力或者说优势呢:
- 更好的泛化能力,大模型通常具有更强大的学习能力和泛化能力,能够在各种任务上表现出色
- 语义理解和生成能力,大模型可以更好地理解人类语言的语义,并生成更流畅、自然的文本、图像和音频内容
- 多模态学习,大模型能够处理多种类型的数据,如文本、图像、声音等,并实现跨模态的学习和生成。
- 迁移学习和预训练,大模型可以通过在大规模数据上进行预训练,然后在特定任务上进行微调,从而提高模型在新任务上的性能。
- 对话和交互能力,大模型可以进行更自然、流畅的对话和交互,实现更智能的人机交互体验。
- 创造性和创新,大模型可以生成创新性的内容,如艺术作品、音乐、故事等,有助于推动创意产生。
- 自监督学习,大模型可以通过自监督学习在大规模未标记数据上进行训练,从而减少对标记数据的依赖,提高模型的效能。
- 个性化和适应性,大模型可以根据用户的需求和偏好生成个性化的内容,提供更符合用户期望的服务。
- 自动化和效率,大模型可以自动化许多复杂的任务,提高工作效率,如自动编程、自动翻译、自动摘要等。
ChatGPT、GPT-4 等的发布,让我们在见识到大模型(LLM)的魅力后,伴随而来的是其所面临的各种挑战:
- 大模型有时会犯事实性错误,也就是可靠性问题(俗称“幻觉”)。例如,它会弄错诗词作者。从原理看,大模型的答案选择基于概率,所以很难保证百分百正确。
- 大模型的数学和逻辑推理能力仍然需要加强。虽然GPT-4在某些考试中表现优异,但在面对一些精心设计的逻辑推理问题时,大模型的回答与随机答案相差无几。因为在进行深度推理时,即便大模型每一步的预测准确率都高达95%,但是当推理到20步时,最终的准确率将会是0.95的20次方,即不到36%,这是一个无法令人满意的结果。
- 大模型的形式语义理解能力有待提升。虽然大模型在一定程度上能够实现语义理解,但要想真正从意义和形式上完全理解语言背后的意义,还有很大的改进空间。
- 大模型作为一个黑盒模型,存在一些通用弱点。比如,其可解释性、可调试的能力较弱等。
- 数据安全隐患:一方面大模型训练需要大量的数据支持,但很多数据涉及到机密以及个人隐私问题,如客户信息、交易数据等。需要保证在训练大模型的同时保障数据安全,防止数据泄露和滥用。
- 成本高昂:大模型的训练和部署需要大量的计算资源和人力资源,成本非常高昂。对于一些中小型企业而言,难以承担这些成本,也难以获得足够的技术支持和资源。
OpenAi介绍
做为引领大模型发展的公司,OpenAI的接口和能力也做为了其他大模型的标准,这里介绍一下OpenAi官方提供的一些能力
聊天
将消息列表作为输入,并返回模型生成的消息作为输出
from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Who won the world series in 2020?"}, {"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}, {"role": "user", "content": "Where was it played?"} ] ){ "choices": [ { "finish_reason": "stop", "index": 0, "message": { "content": "The 2020 World Series was played in Texas at Globe Life Field in Arlington.", "role": "assistant" }, "logprobs": null } ], "created": 1677664795, "id": "chatcmpl-7QyqpwdfhqwajicIEznoc6Q47XAyW", "model": "gpt-3.5-turbo-0613", "object": "chat.completion", "usage": { "completion_tokens": 17, "prompt_tokens": 57, "total_tokens": 74 } }函数调用
将大型语言模型连接到外部资源。在 API 调用中,您可以描述函数,并让模型智能地选择输出包含参数的 JSON 对象,以调用一个或多个函数。聊天 API 不调用该函数,相反该模型会生成可用于在代码中调用函数的 JSON数据。
这里我以实时获取天气预报为例子演示函数调用的流程:
# 获取天气函数 def get_weather(city_name: str): url = "获取天气信息的api地址" params = {"city": city_name} response = requests.get(url=url, params=params) # 返回结果: # {'adcode': '440300', # 'city': '深圳市', # 'humidity': '81', # 'humidity_float': '81.0', # 'province': '广东', # 'reporttime': '2023-06-14 15:00:43', # 'temperature': '29', # 'temperature_float': '29.0', # 'weather': '大雨', # 'winddirection': '西南', # 'windpower': '≤3'} return response.json()这个函数就是用来查询天气情况的,参数 city_name 是城市的名字,接口返回的结果中包含有温度(temperature)、风度(windpower)、风向(winddirection)、湿度(humidity)、天气(weather)等字段信息。
天气函数准备好后,用户开始提问:“深圳天气如何?“, 第一次调用`ChatCompletion`接口。
response = openai.ChatCompletion.create( model="gpt-3.5-turbo-0613", messages=[{"role": "user", "content": "深圳天气如何?"}], functions=[ { "name": "get_weather", "description": "获取指定地区的当前天气情况", "parameters": { "type": "object", "properties": { "city_name": { "type": "string", "description": "城市,例如:深圳", }, }, "required": ["city_name"], }, } ], function_call="auto", )这里我们指定了一个functions 参数,该参数描述了函数的名字以及参数类型,比如我们这里定义了city_name的参数,gpt 就会从用户问题中提取出city_name。 response的返回结果是:
{ "choices": [ { "finish_reason": "function_call", "index": 0, "message": { "content": null, "function_call": { "arguments": "{\n \"city_name\": \"深圳\"\n}", "name": "get_weather" }, "role": "assistant" } } ] }GPT 给我们返回的message中有function_call 字段,而且 arguments 里面提取了city_name这个字段的值。 第二步:从返回结果中提取参数后调用函数, 这个过程不是交给GPT处理,而是由开发者自己调用该函数,GPT做的事情是把函数需要的参数提取出来。
message = response["choices"][0]["message"] function_call = message.get("function_call") if function_call: arguments = function_call.get("arguments") arguments = json.loads(arguments) function_response = get_weather( city_name=arguments.get("city_name"), ) function_response = json.dumps(function_response)第三交步:把返回结果给GPT来做总结归纳
second_response = openai.ChatCompletion.create( model="gpt-3.5-turbo-0613", messages=[ {"role": "user", "content": "深圳今天的天气?"}, message, { "role": "function", "name": "get_weather", "content": function_response, }, ], ) return second_response注意messages列表中最后一条消息中role角色是 function, 最后得到的结果second_response中的content内容为:
content: 深圳今天的天气是大雨,气温为25℃,风向是西北风,风力为3级,湿度为95%。图像生成
使用 DALL·E 的图像 API 提供了三种与图像交互的方法:
- 根据文本提示从头开始创建图像
- 让模型替换预先存在的图像的某些区域来编辑图像
- 创建现有图像的变体
图像理解
GPT-4 with Vision允许模型接收图像并回答有关图像内容的问题。
文本转语音
将文本转换为逼真的语音音频
from pathlib import Path from openai import OpenAI client = OpenAI() speech_file_path = Path(__file__).parent / "speech.mp3" response = client.audio.speech.create( model="tts-1", voice="alloy", input="Today is a wonderful day to build something people love!" ) response.stream_to_file(speech_file_path)语音 API 支持使用块的方式实时传输音频流,这意味着可以在生成完整文件之前播放。
from openai import OpenAI client = OpenAI() response = client.audio.speech.create( model="tts-1", voice="alloy", input="Hello world! This is a streaming test.", ) response.stream_to_file("output.mp3")语音转文本
音频 API 提供两个语音转文本的能力
- 将音频识别为音频使用的任何语言
- 将音频识别并翻译为英语
from openai import OpenAI client = OpenAI() audio_file= open("/path/to/file/audio.mp3", "rb") transcription = client.audio.transcriptions.create( model="whisper-1", file=audio_file ) print(transcription.text)from openai import OpenAI client = OpenAI() audio_file= open("/path/to/file/german.mp3", "rb") translation = client.audio.translations.create( model="whisper-1", file=audio_file ) print(translation.text)
本地部署
现在大语言模型的部署,通常都需要大的GPU才能实现,如果是仅仅想研究一下,我们是很想能够直接在我们的工作电脑上就能直接运行的,llama.cpp就是很好的实现。
LLaMa.cpp 使用量化技术来重新量化权重和使用C/C++来重写LLaMa的推理代码,使其显著降低了内存需求,使得大型语言模型可以在本地的多种硬件上运行,而无需昂贵的GPU。
ChatGLM3是智谱AI和清华大学 KEG 实验室联合发布的大模型。为了实现本地运行推出了类似 llama.cpp 的量化加速推理方案chatglm.cpp
Ollama是一个轻量级、可扩展的框架,用于在本地机器上构建和运行大型语言模型(LLM)。它提供了一个简单的API来创建、运行和管理模型,以及一个预构建模型库,可以轻松用于各种应用程序。
其他介绍
扣子是由字节跳动推出的一个AI聊天机器人和应用程序编辑开发平台,可以理解为字节跳动版的GPTs。无论用户是否有编程经验,都可以通过该平台快速创建各种类型的聊天机器人、智能体、AI应用和插件,并将其部署在社交平台和即时聊天应用程序中。
LangChain是一个用于开发由语言模型驱动的应用程序的框架,允许开发人员将语言模型连接到其他数据源并与其环境相交互。
Hugging Face是一个平台,拥有超过12万个模型、2万个数据集和5万个演示应用程序(Spaces),全部都是开源且公开可用的。
参考链接
[1] 大语言模型实践
[2] 一文教你读懂GPT模型的工作原理
[3] 大模型工具调用原理及实现